← back ·
Where RL training algorithm ends and a Policy starts
From MLP to LLM: Refactoring PPO Policy implementations and introducing modular policy design
In the previous post we implemented the vanilla PPO policy optimization algorithm. In this one we’re going to play around with one crucial component of that vanilla implementation - the policy definition.
Specifically, we’re going to swap out the MLP based policy for one based around one of popular, open-source LLMs (we’ll use Qwen2-0.5B baseline model).
The main goal however is to gain a better understanding of the areas of responsibility of the components that make up a vanilla RL algorithm like that. I admit to often coming away from a whitepaper lecture with an impression that the descriptions of those algorithms conflates a lot of components. This post is an attempt to segregate them into exchangable parts.
This will be a pure software engineering post - we’ll do a fair bit of refactoring and design analysis.
Vanilla PPO architecture refresher
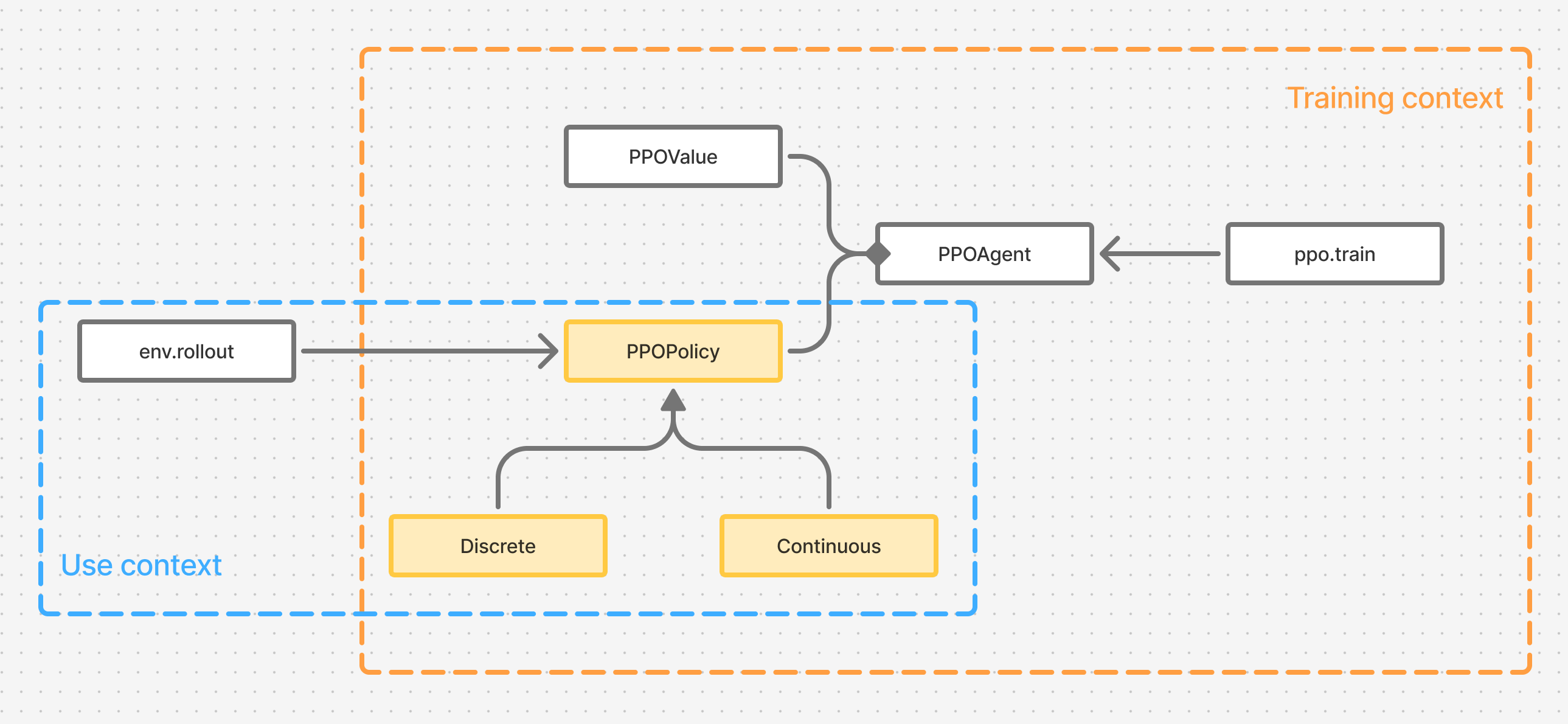
Figure 1. Vanilla PPO architecture in two contexts - when a policy is trained using PPO, and when a trained policy is used in an application.
After coming away from the lecture of the whitepaper and the code, I have to admit that the concept of PPO in my mind span three separate entities - training algorithm, the trained policy and the value function. All three were written to complement and aid the training process.
But if we take a step back and consider other contexts - such as when the policy would be used after training, we notice that we can jetison all of those entities but the policy itself.
The natural question then is how much of what PPOPolicy represents is related to PPO itself? Could we turn it into an entity that’s unrelated to PPO, one that could be trained with other approaches? We’ll complete this exploration in the next post, when we train it with GRPO, but here we’ll try nudging this concept from a different direction.
LLM based policy implementation
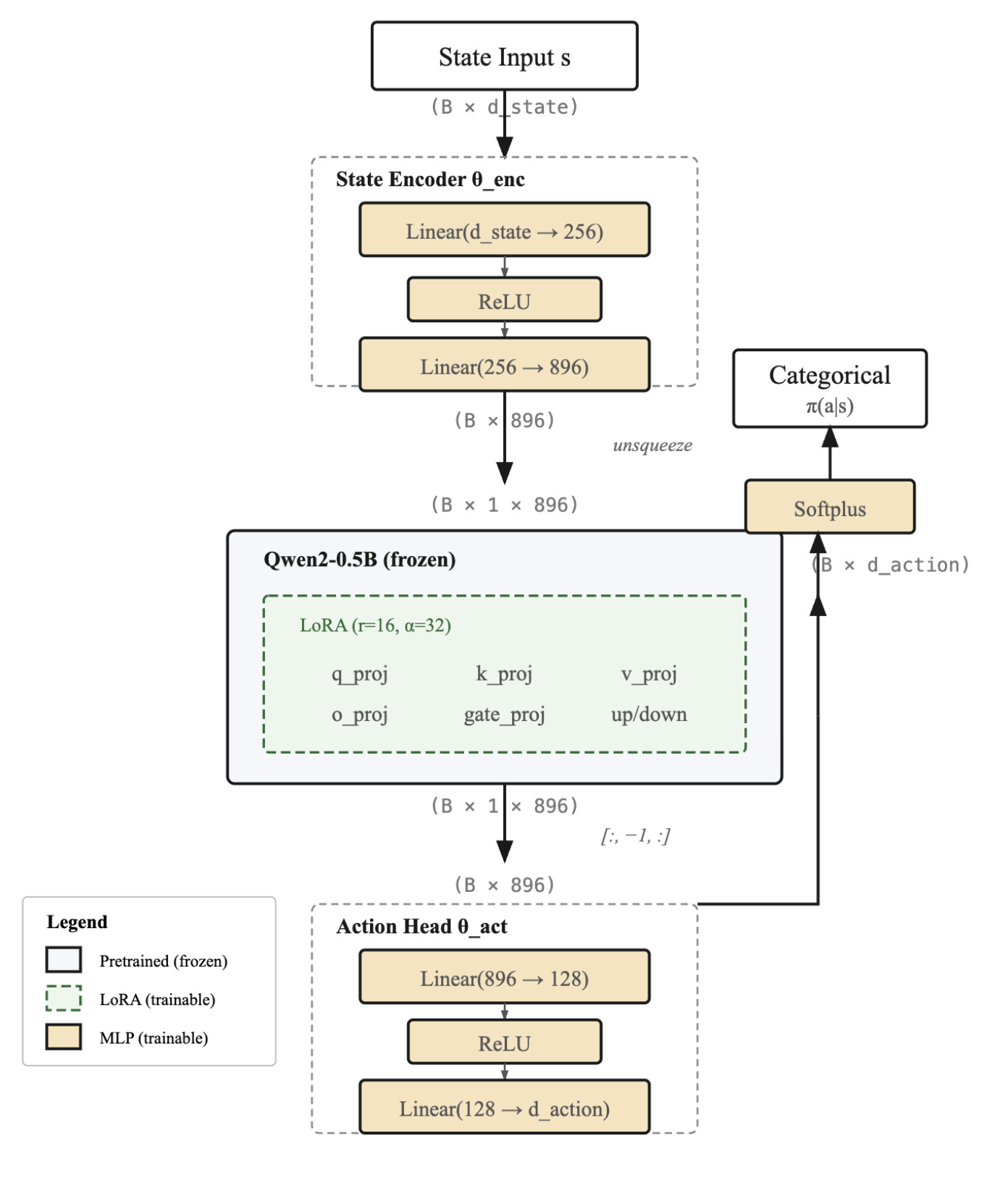
Figure 2. Policy architecture that uses QWEN2-0.5B base model
Our current policy implementations are simple MLPs. Let’s say we wanted to replace it with a foundational language model - what would need to change.
There’s a few questions we need to answer:
Q: Which model to pick - should it be one of large online LLMs, or something small?
The key factors are - our ability to train such a model, speed of execution and cost. I chose QWEN2-0.5B, because I can host it locally and its fairly fast for this little project.
Q: How to even train such a model?
I consider HuggingFace my main model repository. It saves me the trouble of adapting models that were written using different coding best practices.
That commodity hides an important aspect of a model though - access to its parameters. The other confusing aspect is the need to use a Tokenizer to generate input. Tokenizer takes strings as inputs - but we operate with states that are vectors of floating point values rather than strings.
The other issue is the training method - should we train the entire model, or append a few layers to it and train only those, freezing the weights of the underlying model (known as Parameter Efficient Fine Tuning - or PEFT for short)?
Generally speaking, training the entire model can lead to undesired effects, such as loss of generalization. But more importantly - even for a small model like QWEN2-0.5B, it would be very slow and very memory inefficient.
To solve both problems we will therefore use PEFT training method. And lucky for us, HuggingFace offers a neat PEFT implementation in its peft library. This library solves our first issue - access to parameters.
Q: How to bypass the tokenizer?
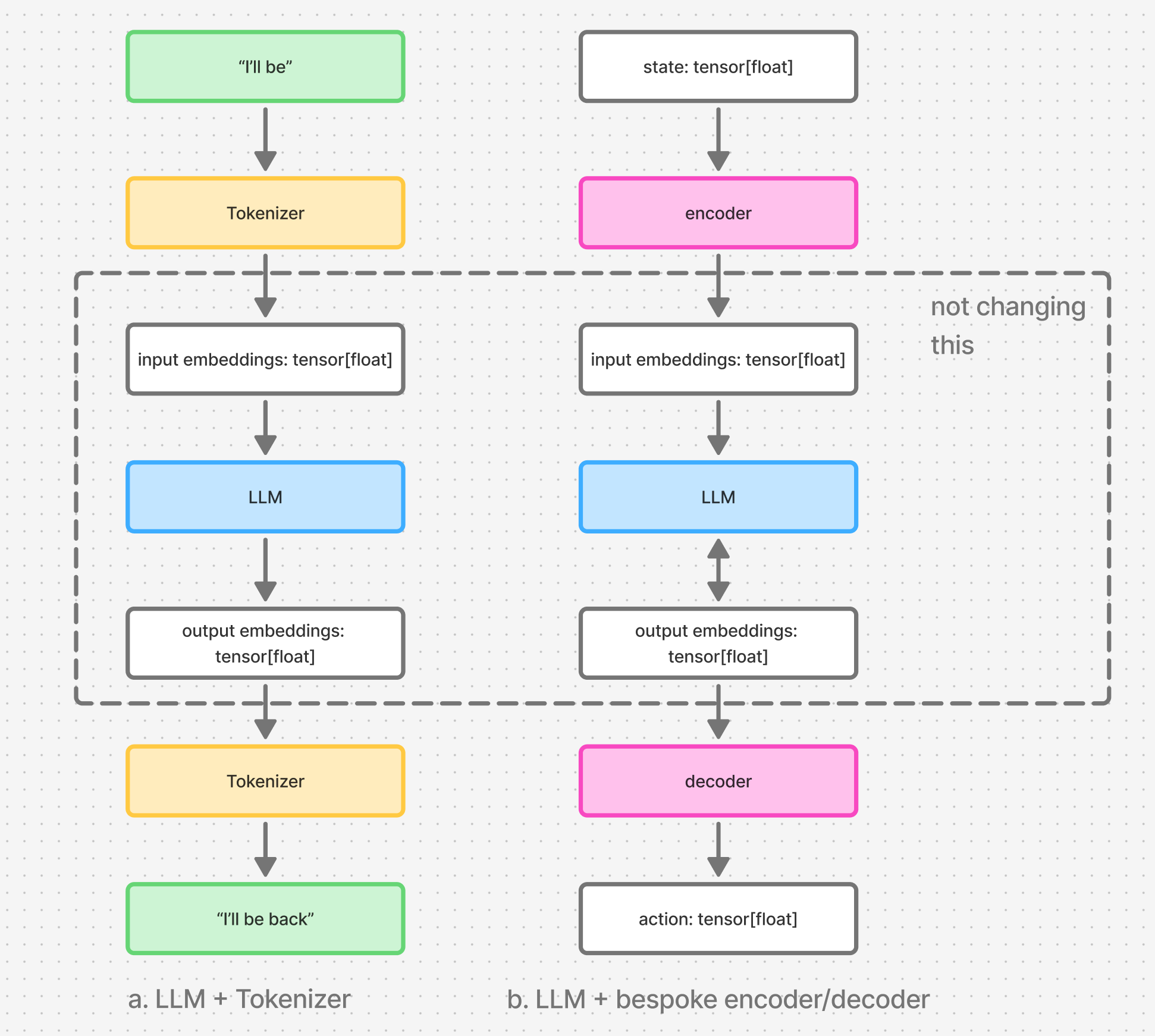
Figure 3. part “a” shows the regular setup in which Tokenizer is used as a string encoder/decoder. part “b” shows the bespoke encoder and decoder we need to introduce to encode the state tensor and decode the action tensor.
Tokenizer acts as an input encoder and an output decoder. It is either jointly trained with the model, or a pretrained tokenizer is used to train an LLM. Either way, the LLM depends on how its tokenizer works.
We will therefore need to train our own encoder and decoder. In this way, we’ll train those new layers to represent the inputs and decode the outputs in a way that best align with the LLM.
The final construct looks like this:
import peft
import transformers as tr
import torch
import torch.nn as nn
llm_id = "Qwen/Qwen2-0.5B"
llm = tr.AutoModelForCausalLM.from_pretrained(llm_id)
peft_config = peft.LoraConfig(
r=16, # rank
lora_alpha=32, # scaling factor
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_dropout=0.05,
)
llm = peft.get_peft_model(llm, peft_config)
llm_hidden_dim = 896
state_encoder = nn.Sequential(
nn.Linear(self.state_dim, 256),
nn.ReLU(),
nn.Linear(256, llm_hidden_dim)
)
action_head = nn.Sequential(
nn.Linear(llm_hidden_dim, 128),
nn.ReLU(),
nn.Linear(128, self.action_hidden_dim),
)
At the end of this code we have 3 entities:
-
state_encoderwhich converts our state to input embeddings to be passed to the LLM -
llmwhich is a LORA wrapper around the base QWEN2-0.5B model -
action_headwhich converts the LLM output to action logits
The following is the code that executes that conversion:
states_embeddings = state_encoder(states)
states_embeddings = states_embeddings.unsqueeze(1)
llm_outputs = llm(
inputs_embeds=states_embeddings,
output_hidden_states=True
)
last_hidden = llm_outputs.hidden_states[-1][:, -1, :]
action_logits = action_head(last_hidden)
MLP based policy refresher
We could express the code above with this pseudocode:
def get_action_logits(state: torch.Tensor) -> torch.Tensor
Let’s see how this compares to our ML Policy implementation:
class PPODiscretePolicy(PPOPolicy):
def __init__(self, state_dim: int, action_dim: int) -> None:
super().__init__(
# ...
)
self.policy = nn.Sequential(
# ...
)
def _get_action_distribution(self, state: torch.Tensor) -> dist.Distribution:
action_logits = self.policy(state)
action_logits_positive = nn.functional.softplus(action_logits)
return torch_utils.CategoricalUnsqueezed(action_logits_positive)
def get_action(self, states: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
actions_dist = self._get_action_distribution(states)
# ...
def evaluate_actions(
self, states: torch.Tensor, actions: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
actions_dist = self._get_action_distribution(states)
# ...
Notice the patterns in this code:
-
__init__is where we initialize our network -
_get_action_distributioncalculates the logits and then wraps them in a distribution -
get_actionandevaluate_actionsuse_get_action_distribution
So for our purpose, we would need to replace the contents of __init__ and the contents of _get_action_distribution.
Let’s go one step further though - we have another version of this class that represents a continuous policy (link to full code from the previous post) - how does it differ from this code?
-
log_probstensor shape is different, so the continuous policy needs to reduce that shape -
torch.distributions.Normalis used instead oftorch.distributions.Categorical
Policy classes refactored
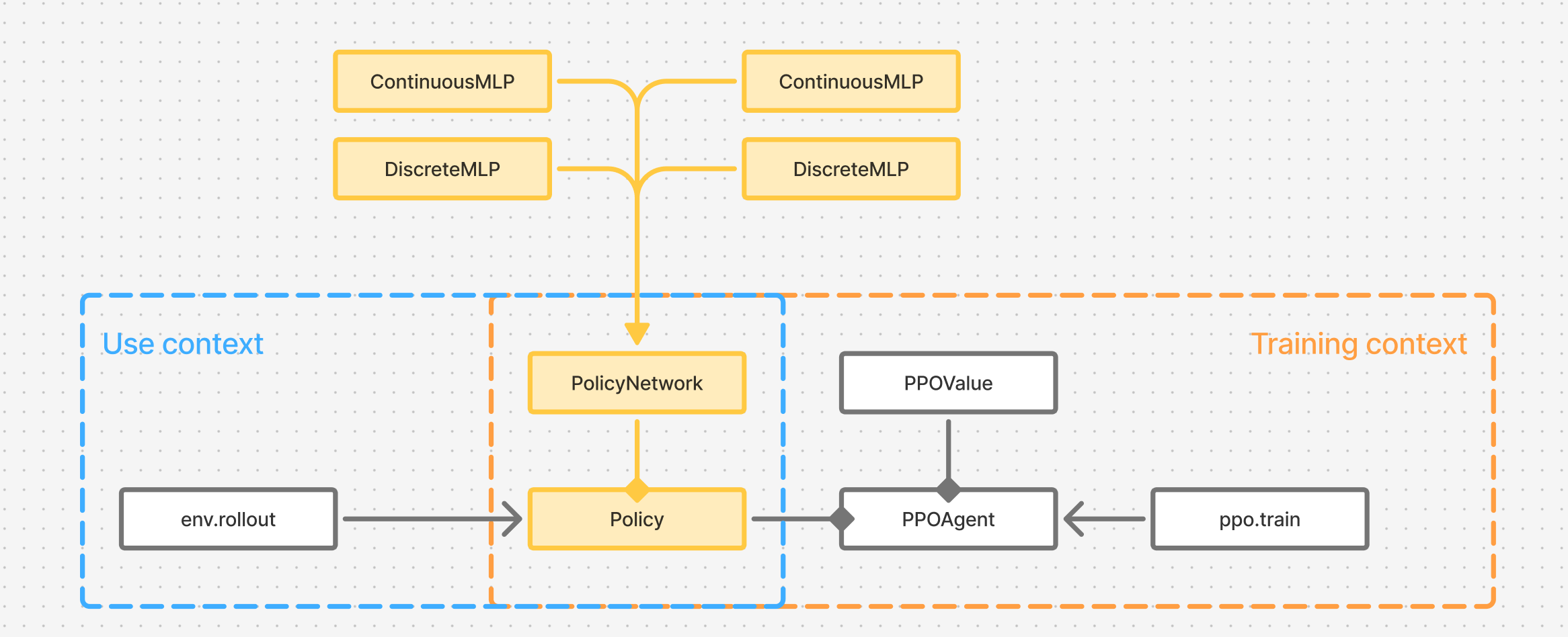
Figure 4. Refactored Policy is now a final class, strategized with a PolicyNetwork implementation.
What changes is network creation & distribution calculation What stays the same is - get_action and evaluate_actions.
This leads to refactoring shown in Figure 4 - where Policy class will be closed and finalized, owning the methods for getting an action and evaluating actions coming from other policies.
The responsibility for caclulating the distribution of actions given input states will fall to different implementations of PolicyNetwork.
Let’s consider for a moment what Policy class now represents though. It works with distributions of actions, and it samples those distributions to generate actions. It is a StochasticPolicy, as opposed to a deterministic policy that would employ a non-probabilistic mechanism for generating actions.
Summary
As Figure 4 also shows, we have now, to a degree, isolated the concept of Policy from PPO.
Is that separation complete ? That depends on:
-
whether PPO would work with deterministic policies
-
whether out Stochastic policy could be trained using algorithms other than PPO (e.g. MPO, TRPO, GRPO etc.)
In the next posts I’ll try to answer some of those questions. Thank you for reading !