← back ·
Teaching Claude to Create Pixel Art
Are Agentic Frameworks just slow, imperfect Finetuning frameworks ?
The Challenge
Like many developers working with AI assistants, I’ve noticed that Claude is quite good at understanding concepts, analyzing patterns, and explaining techniques—but there’s a significant gap between knowledge and capability.
With the recent conversations about the ever improving LLM capabilities, and the agentic frameworks approaching singularity, I thought I’d put Claude to the test.
Generating a pixel art character using Claude Opus 4.5
The challenge I selected was something that lies slightly outside Claude models area of expertise. I wanted to see how the model itself, and The agentic framework built around it - Claude code - can handle such a task and potentially self improve in order to execute it.
I started with this image downloaded from the internet and this prompt:
{kind=link}

Here's a reference image. Can you generate a 64x64 pixel art image of a character, a detective in a coat with the extracted style and palette.
The result I got was:

This is not bad, however it’s far from some of the pixel art characters one can see in video games. Here’s an example:
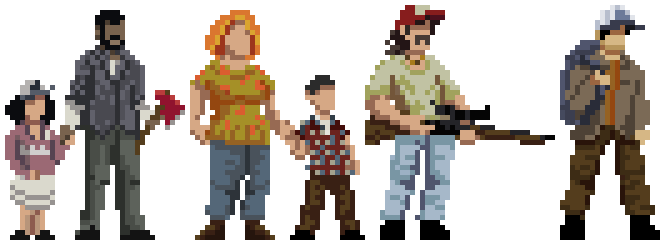
Claude Code + Skills
I started with the following prompt
You are not great at creating pixel art graphics.
I want you to create a skill that would allow you to: analyze reference pictures, understand the style/composition/color palette/how to represent game characters/buildings/scenery/mood, and render pixel art images based on prompts.=
Leveraging the Claude Skills, the model generated three skills that, given a reference image, would analyze the style & color palette and rendering a pixel art image.
Claude successfully analyzed the style (”Dark atmospheric pixel art with warm lighting accents”), extracted a 64-color palette organized by function (sky gradients, house structure, warm lighting), and identified key techniques like dithering and color banding - so far so good.
But then came the rendering test. I prompted Claude to create:
A character, a detective in a coat with the extracted style and palette, 32x32
… and another with a slightly higer resolution. The result was… disappointing.

Strange shapes, flat colors, and a character that looked nothing like a detective. The results remained poor. The approach was fundamentally flawed.
The Retrospective
I prompted Claude to analyze its own failure:
The results are disappointing - flat colors, strange shapes, bad design (not to mention very strange look of the character). Analyze your approach and explain why the skill you generated doesn’t give you ability to generate good pixel art
Some of Claude’s self-analysis was remarkably insightful. The response it generated explained that it had extensive knowledge about pixel art theory, but knowing these principles doesn’t translate to being able to apply them.
…Some however were outright hallucinations. It claimed the core problem was no visual feedback. As I mentioned at the beginning, it’s a multi-modal model that takes images as input. One might potentially consider this to be true - after all, an .svg document is an XML - however it is also a widely recognized vector graphics image, and I would assume that if the authors of the model went to lenghts of making it the output format of choice, they would go to pains of training the model with this format as input.
Pivoting to Blender 3D
I decided to give the approach one more go - this time by pivoting to Blender 3D. There were a few reasons:
-
there are MCP servers for Blender 3D on GitHub
-
there is ample documentation on Blender 3D API
-
… Claude generated that suggestion itself !
That last part is particularily important - but I don’t want to focus on it now, so let’s put a pin in it.
Claude generated the new skills and started rendering my character. This is the result:
What was this experiment really about
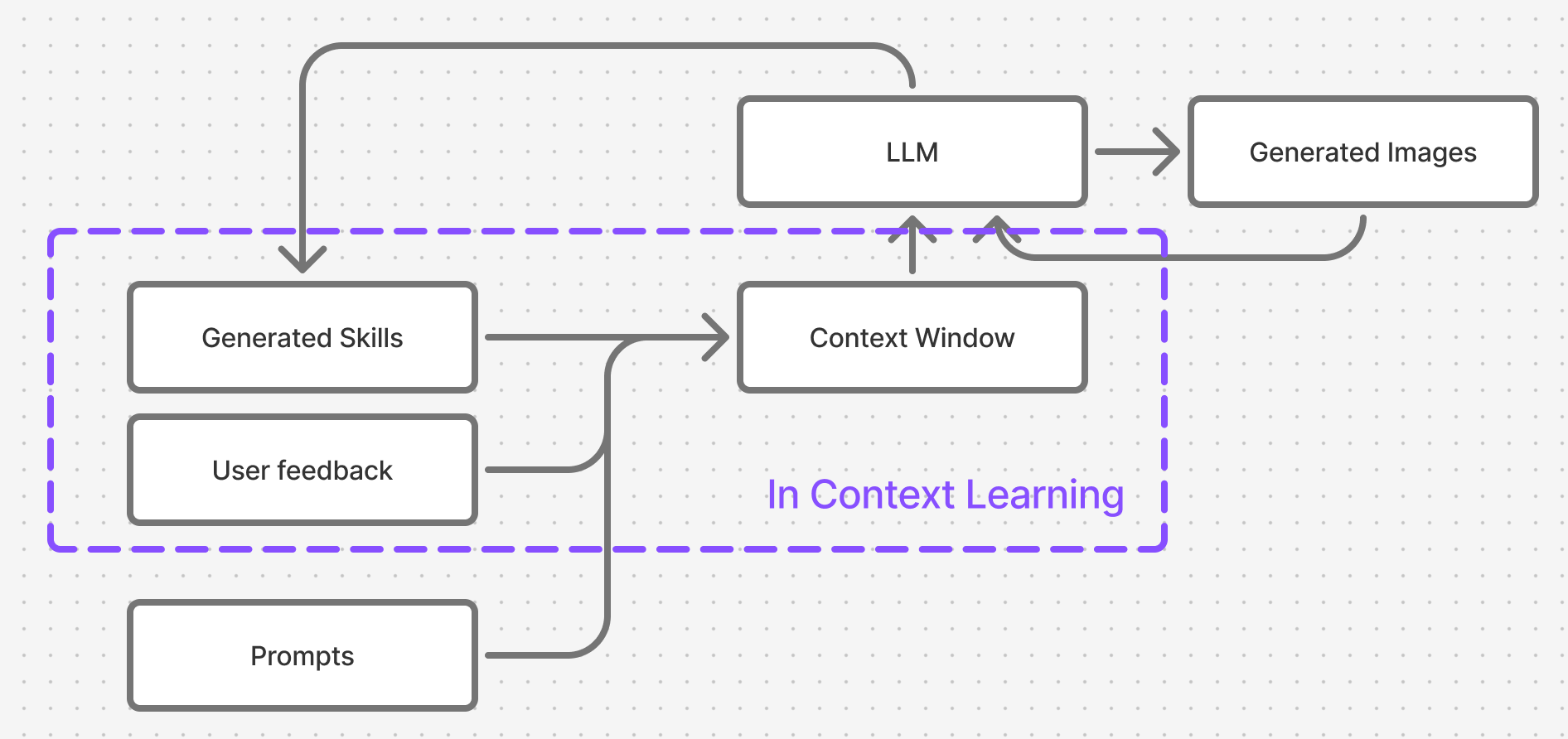
This was an example of In-Context Learning - the key technique Agentic Frameworks like Claude Code use to perform tasks and improve over time.
The agent was tasked with exploring an unknown domain, learning how to solve tasks in that domain, and ultimately demonstrating that newly acquired ability.
To achieve that it had at its disposal:
-
one of the most powerful LLMs (Anthropic Claude Opus 4.5) capable of reasoning , planning and tool execution
-
access to all of the built-in tools Claude Code comes with
-
unlimited thinking time
Finetuning perspective
The agent went ahead and build up a training dataset (skills, human feedback, reference images). It then used that information as input to an autoregressive model, effectively changing the model’s original output token distribution given the same prompt.
If we denoted the prompt to generate the character as X, all of the prompts that led to the model building skills as Y, the generated image as Z and the ideal (expected) image as Z’, then we would expect that:
and thus that the model would learn how to better generate to our expectations.
But the results we obtained do not indicate any learning whatsoever. Quite the contrary - each step introduced a significant degradation wrt. the baseline.
Is this form of training effective?
The key observation while working with Claude Code was that didn’t actually attempt to learn
-
It generated the skills - as in hallucinated them. It didn’t search for any online resources.
-
It didn’t attempt to test the skills it generated - it didn’t generate any images of its own volition, as a part of the process. I needed to do it myself, and then provide feedback
It therefore didn’t follow any learning process in the classical sense of word - create a train set, modify its beliefs, evaluate them on the test set, lather rince and repeat.
The actions it took also didn’t make it easy to understand what kind of feedback would be most useful to inject:
-
how to “refactor” the skills it generated to make them better.
-
what data to inject
In addition, the framework used context window compression which degraded the quality of the information it learned. The compression ran just before the Blender 3D skill refactor.
Skills as latent knowledge representation
The Skill definitions themselves are quite an interesting thing. It’s completely unclear how to write them or what to change in order to make them better.
Or more specifically - if a random word / sentence was removed or added to a Skill definition, to what degree would it affect the generation result.
Conclusion
This experiment in my opinion shows three large drawbacks of agentic frameworks:
-
they are learning systems, but the learning techniques that apply to them are not well documented
-
they build on top of LLMs and it looks that they can only achieve results as good as the underlying LLM
-
The systems thenselves do not readily help the developer build a working training framework to improve on a particular skill - this still seems to belong to the aesotheric “prompt engineering”, with little science explaining how to author prompts to achieve desired effects.
I’m convinced that, given enough time and effort one can coin sets of Skills that will aid an LLM to perform an arbitrary task - but is it worth it given the powerful finetuning techniques we have at our disposal ?
Thank you for reading !