How difficult is it really?
Deep Learning whitepapers are not straightforward to implement. They require multiple readings, reading related literature, multiple iterations and lots of trial and error.
It makes the task of implementing and engineering research breakthroughs an arduous tasks, especially for less experienced engineers.
I would like to show how that might look like on a random paper I selected.
Proximal Policy Optimization Algorithms (PPO)
…is an on-policy policy gradient reinforcement learning algorithm arXiv:1707.06347
I chose this one for a few reasons - it stood the test of time, is widely used and generic and several baseline implementations exist (e.g. ClearRL PPO) - these qualities make it a very worthwhile piece of code to implement and understand.
But most important of all - despite the being a high quality paper, I found the experience of reading it very similar to many other Deep Learning whitepapers. So it’s not an outlier, but a good representative on the class of problems I want to focus on.
First read of the paper
I want to take you, my dear reader, on a journey. And that means you need to get your feet dirty to fully appreciate the experience.
So please click on the link below and read the original whitepaper. Approach it with a sense of curiosity that you need knowing that in a moment you will need to implement it. Please note your observations somewhere.
You may or may not be familiar with Reinforcement Learning. No matter your experience, I will assume you have no clue about it this is your first experience with it. I will however assume that you are a software engineer - you have a working knowledge of a select programming language (we’ll be using Python here), basic data structures and algorithms, code complexity management, testing your code.
Go ahead - arXiv:1707.06347 - come back here when you’re done.
Engineering approach to implementation
The first order questions I will attempt to answer are:
Note that we are translating a paper to an implementation, rather than designing our own algorithm/system - therefore we don’t need to worry about defining and fulfilling functional and non-functional requirements.
Evaluation
In terms of evaluation we can find references to various RL environments the original paper was evaluated on in sections Experiments and Appendix B:
-
environments that have been moved to OpenAI Gymnasium since the publication of this paper
-
Roboschool has been deprecated, and the link to PyBullet mentioned in the deprecation note no longer works
OpenAI Gymnasium is well documented and has a standardized environment API which allows to interact with any environment using the same code.
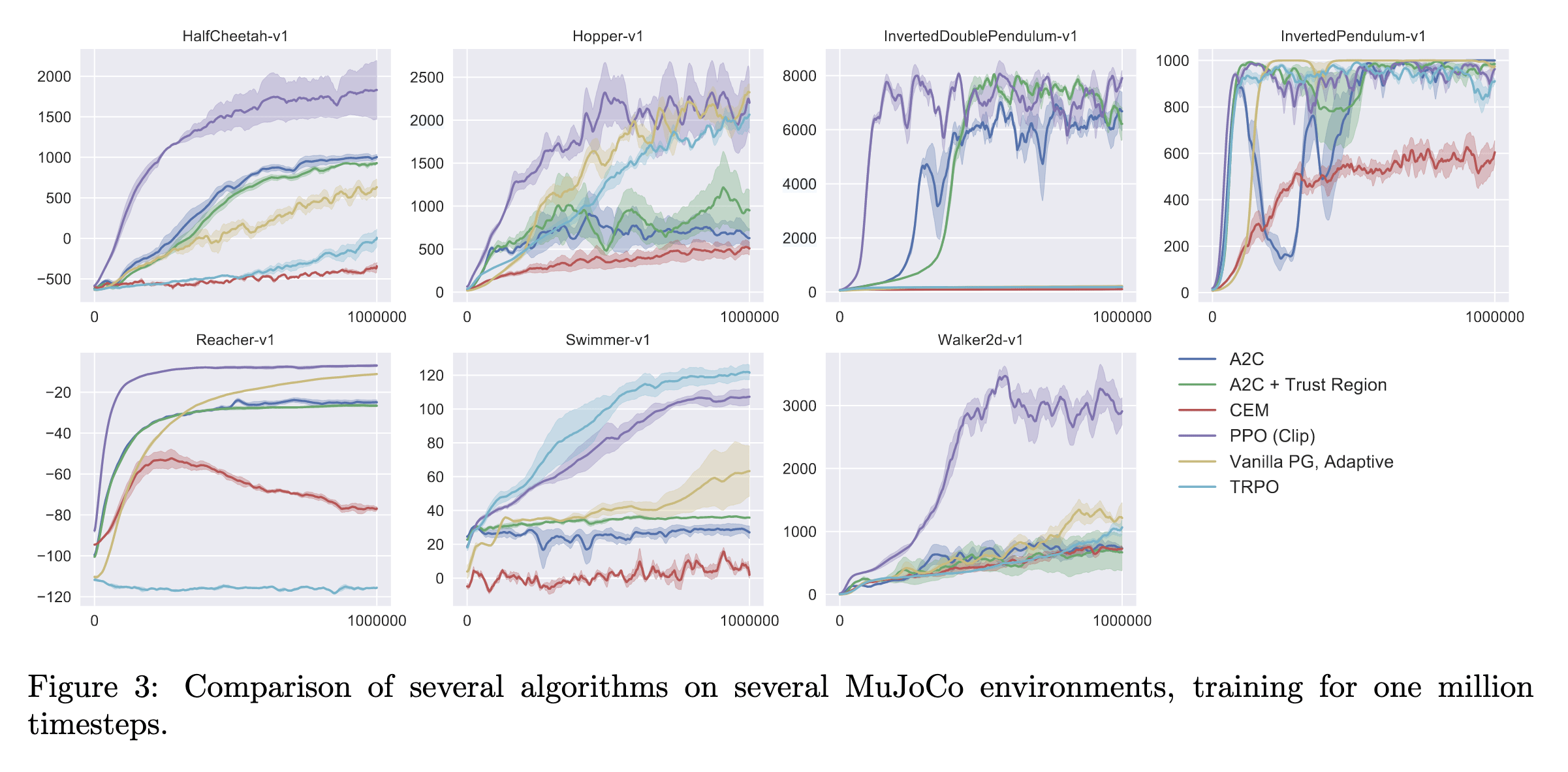
Cumulative score from each environment is used as the metric. Notice that the scores are specific to each environment (different Y axis scales):
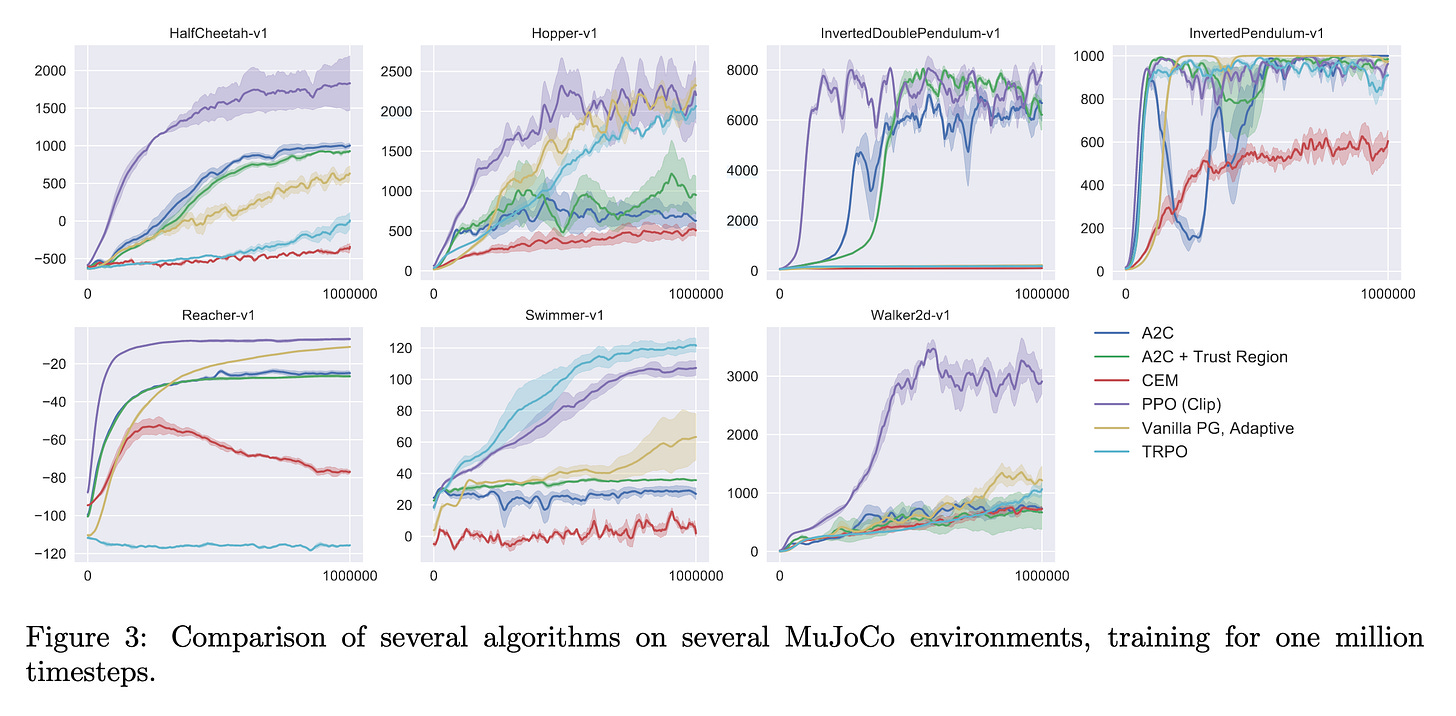
Figure 1. Example PPO evaluation plots
The X axis on the plots refers to the evaluation scores obtained after x training steps.
Based on this information, we can develop the following framework:
import logging
import gymnasium as gym
def evaluate(**evaluated_algo: ???** , training_step: int) -> None:
eval_environment_ids = ["HalfCheetah-v1", "Hopper-v1", "Swimmer-v1", ] # ... add others
for env_id in eval_environment_ids:
env = gym.make(env_id)
# Use the standardized OpenAI Gumnasium API to run the environments
observation = env.reset()
episode_finished = False
score = 0
while not episode_finished:
**action = evaluated_algo(observation)** observation, reward, episode_finished, _, _ = env.step(action)
score += reward
logging.info("Score for %s after training step %d is %f", env_id, training_step, score)
I highlighted the two open questions:
-
what exactly is the implemented algorithm is still unclear
-
we can technically figure out that the implemented algo is supposed to convert observations returned by the environment into actions that will be fed back to the environment - this information is NOT mentioned in the paper however.
Arcane knowledge
The second point specifically requires the reader to scale the ladder of references and build an understanding of what is the essence of Reinforcement Learning algorithms.
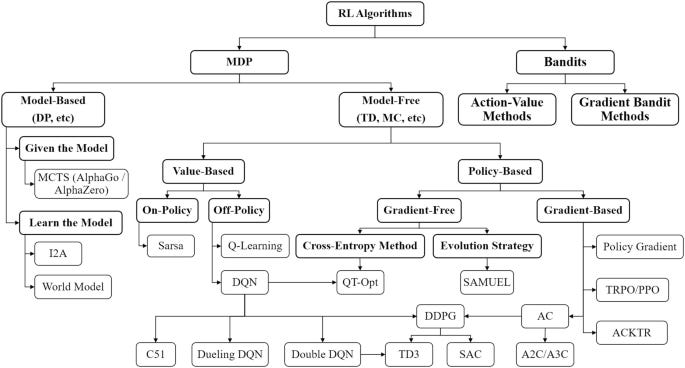
Today, with ample resources, RL is not a mystery it used to be in year 2017, when this paper was originally published. Back then however, this was arcane knowledge, with few materials and fewer available example implementations. What was worse - the knowledge that existed introduced such vast terminology that it was very difficult to piece a cohesive understanding of these algorithms easily.
This led (in my case, and perhaps in yours too) to loosing the forest for the trees - instead of being able to implement e.g. PPO, one had to first undestand “on-policy”, “off-policy”, “gradient policy”, “policy functions”, “value functions”, “Bellman equation”, “losses”, “rewards - sparse and dense” …
Just take a look for yourself:
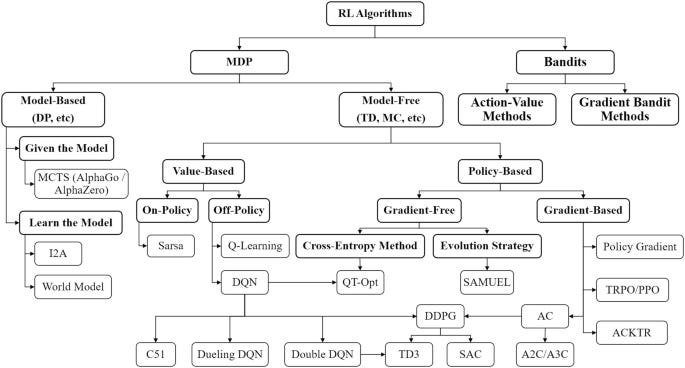
Figure 2. Taxonomy of Reinforcement learning models, Springer
And here’s a very good overview paper - arXiv:2209.14940v
This approach is employed by 99% of the whitepapers I’ve read during my career, and makes each of them a delta that builds on top of other information, rather than a self contained thing.
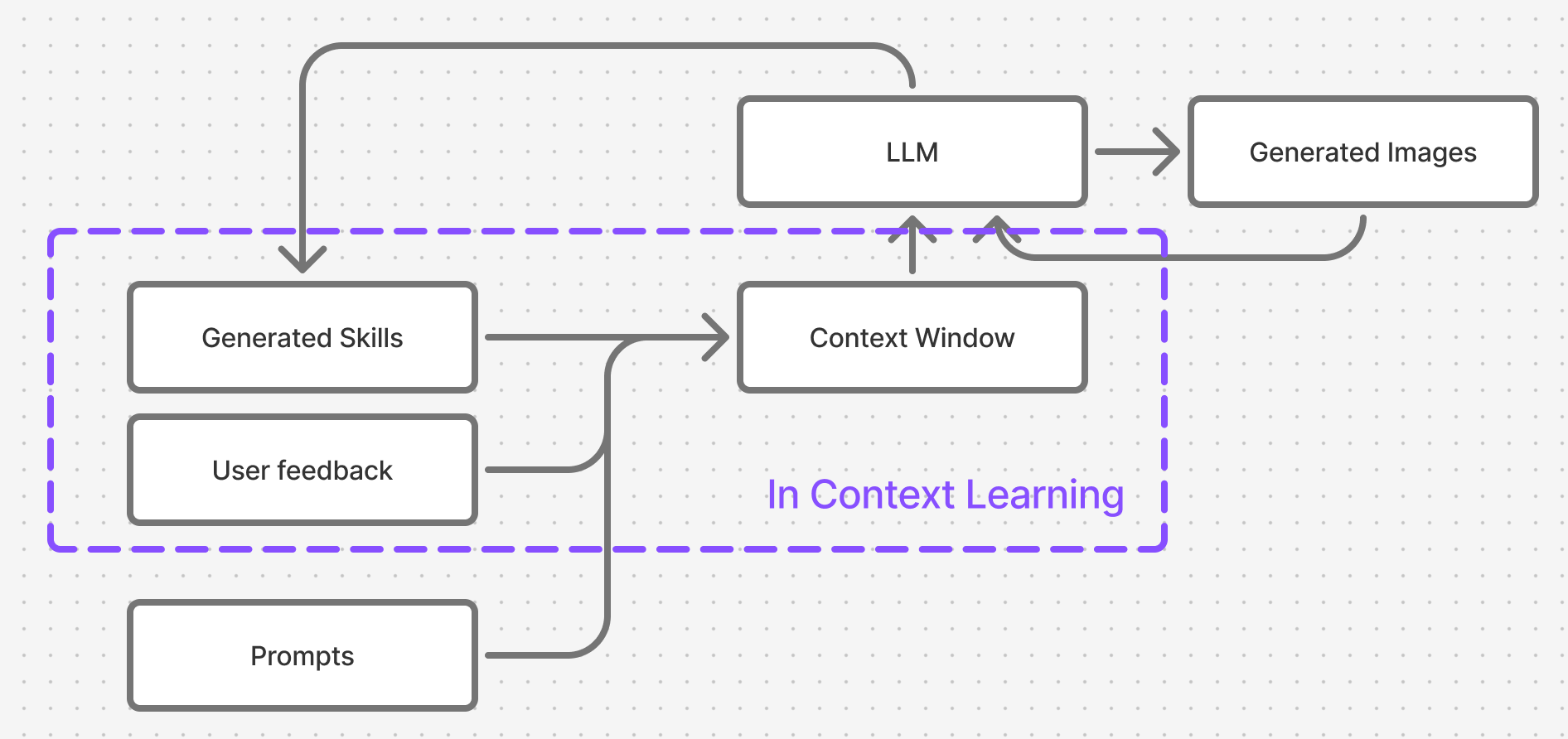
Arcane knowledge of Reinforcement Learning demistified
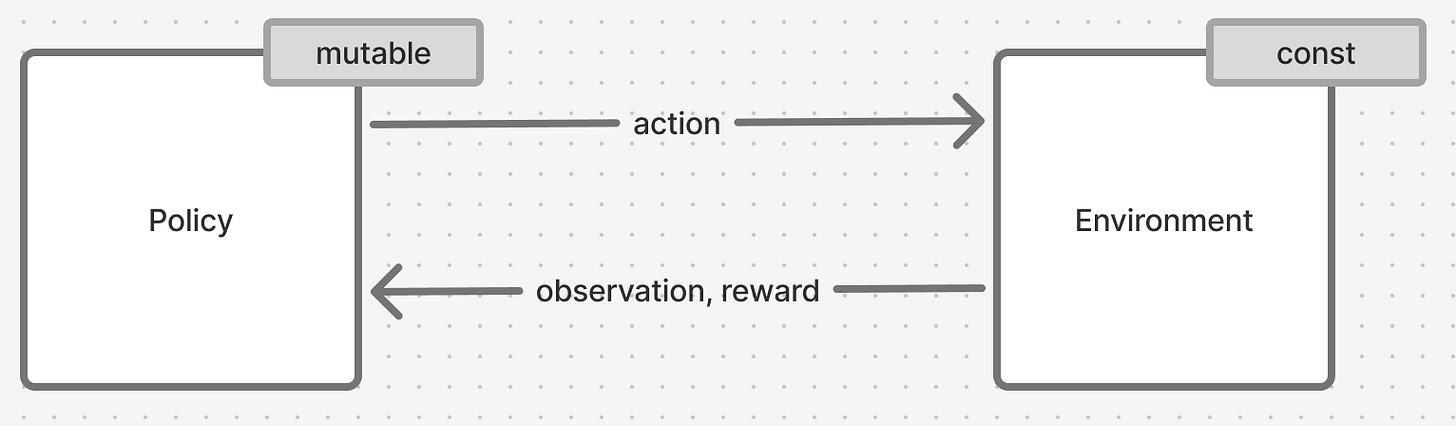
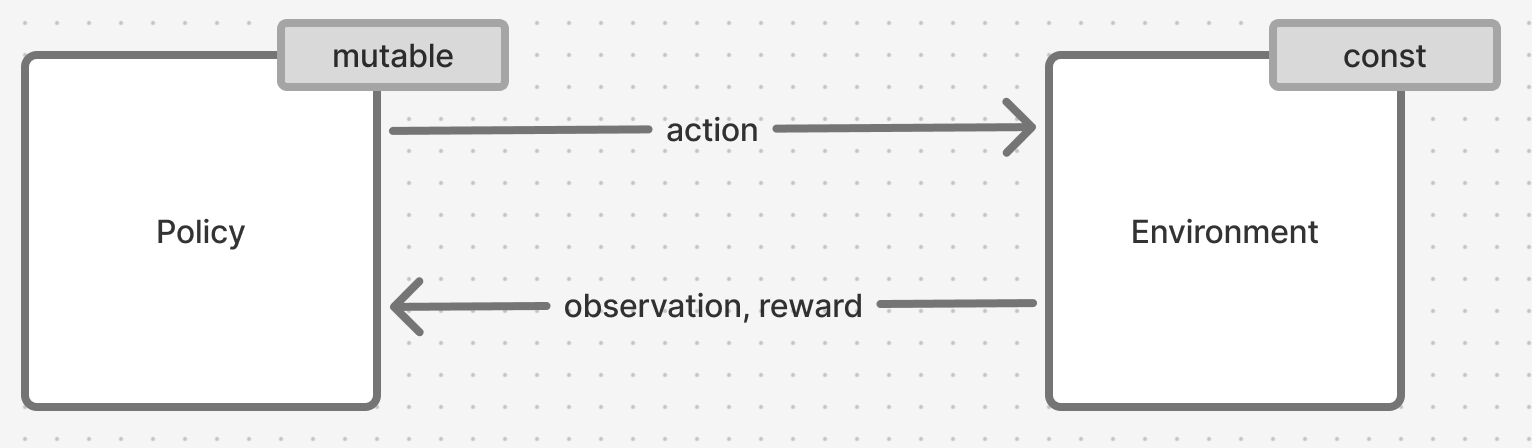
Figure 3. Reinforcement learning system, simplified view
Reinforcement Learning describes a system of 2 entities - an environment and a policy, that trade 3 key pieces of data between themselves: observations (sometimes referred to as state), actions and rewards.
Both can be thought of as functions:
def environment(action) -> tuple[observation, reward]:
pass
def policy(observation, reward) -> action:
pass
The “learning” part of Reinforcement Learning system pertains to that reward signal we are passign to the policy - we are stating that the policy learns and changes its definition based on that signal. Environment on the other hand never changes its definition and stays constant.
How the policy learns - that is the real reason behind such diversity of methods shown in Figure 2 - some versions learn from each action, some require massive amounts of accumulated data, and some use auxiliary entities.
Enter PPO.
PPO demistified
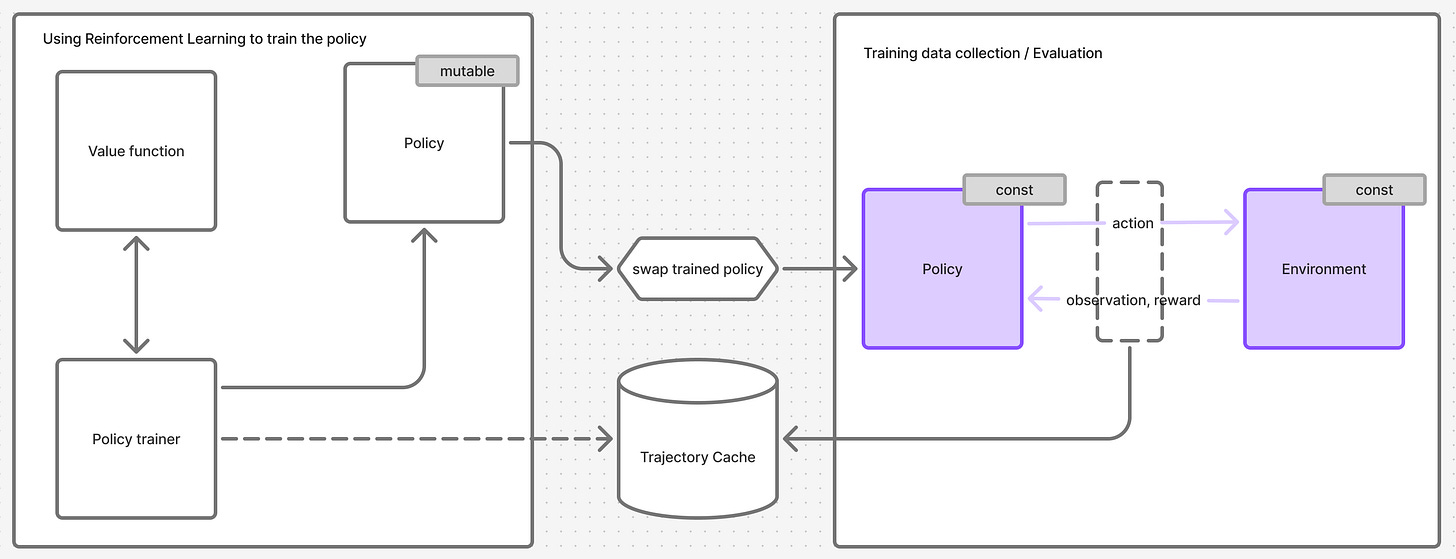
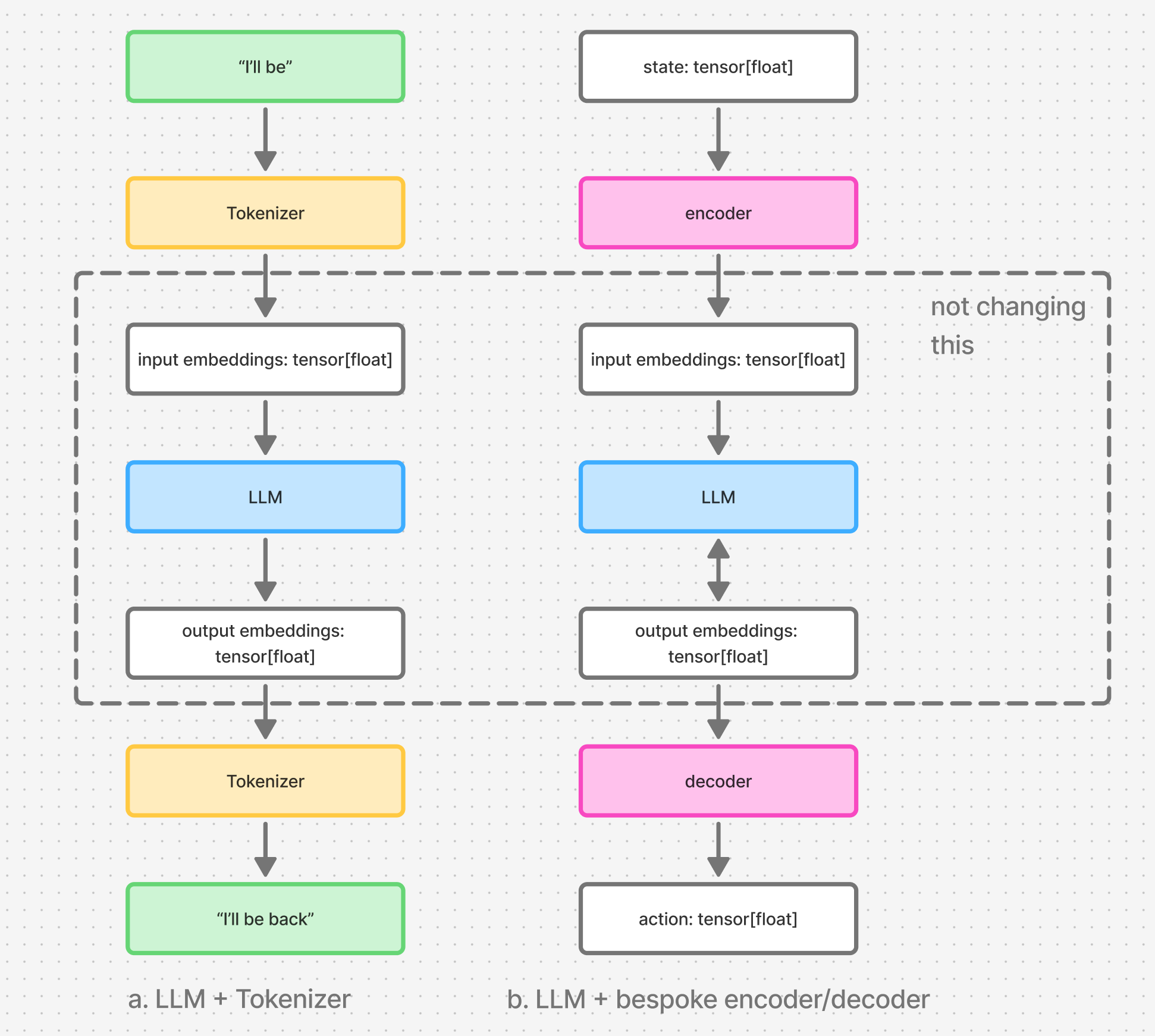
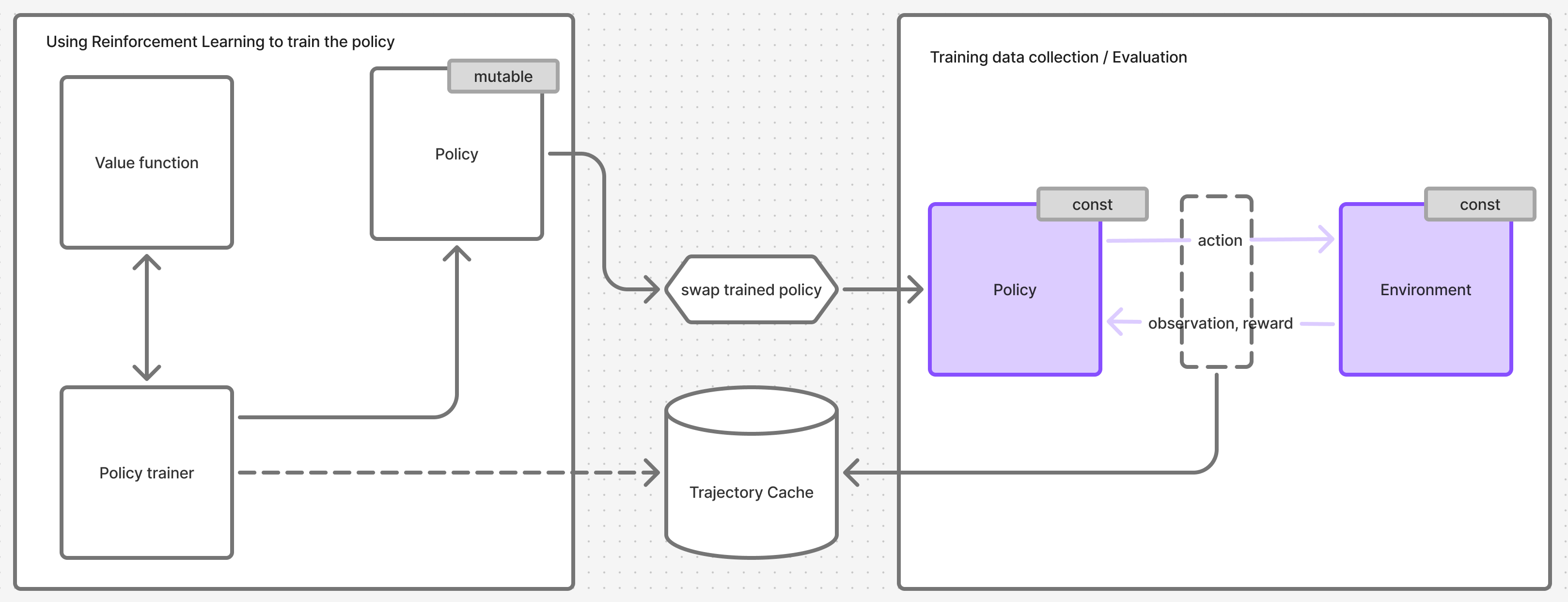
Figure 4. PPO overlayed on top of the training system. System from Figure 3 colored purple.
I arrived at the diagram in Figure 4 by stitching the information scattered across chapters 2, 3, 5 and 6. That information has to be grafted onto a framework that the paper does not mention but assumes familiarity with.
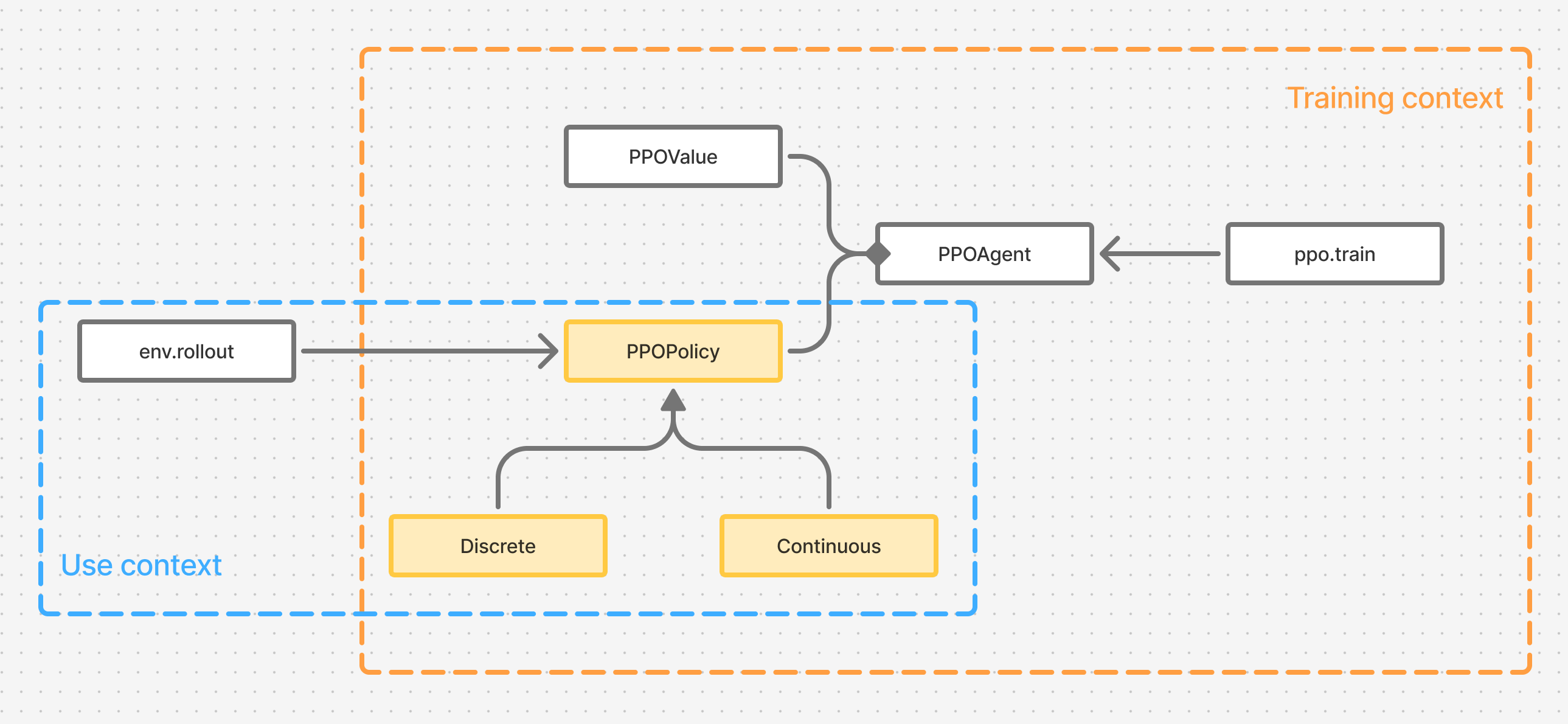
Step 1 overall PPO training algorithm
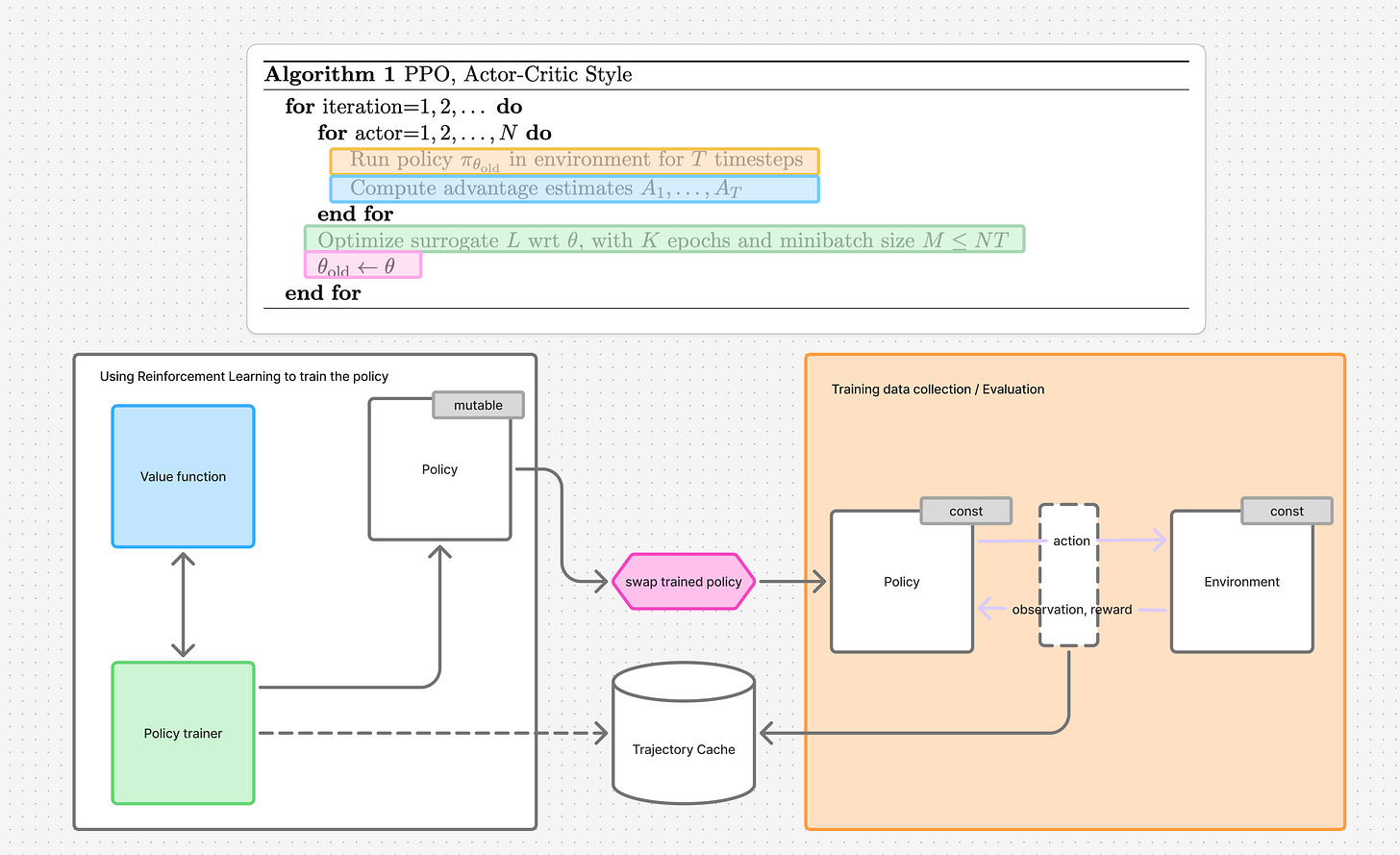
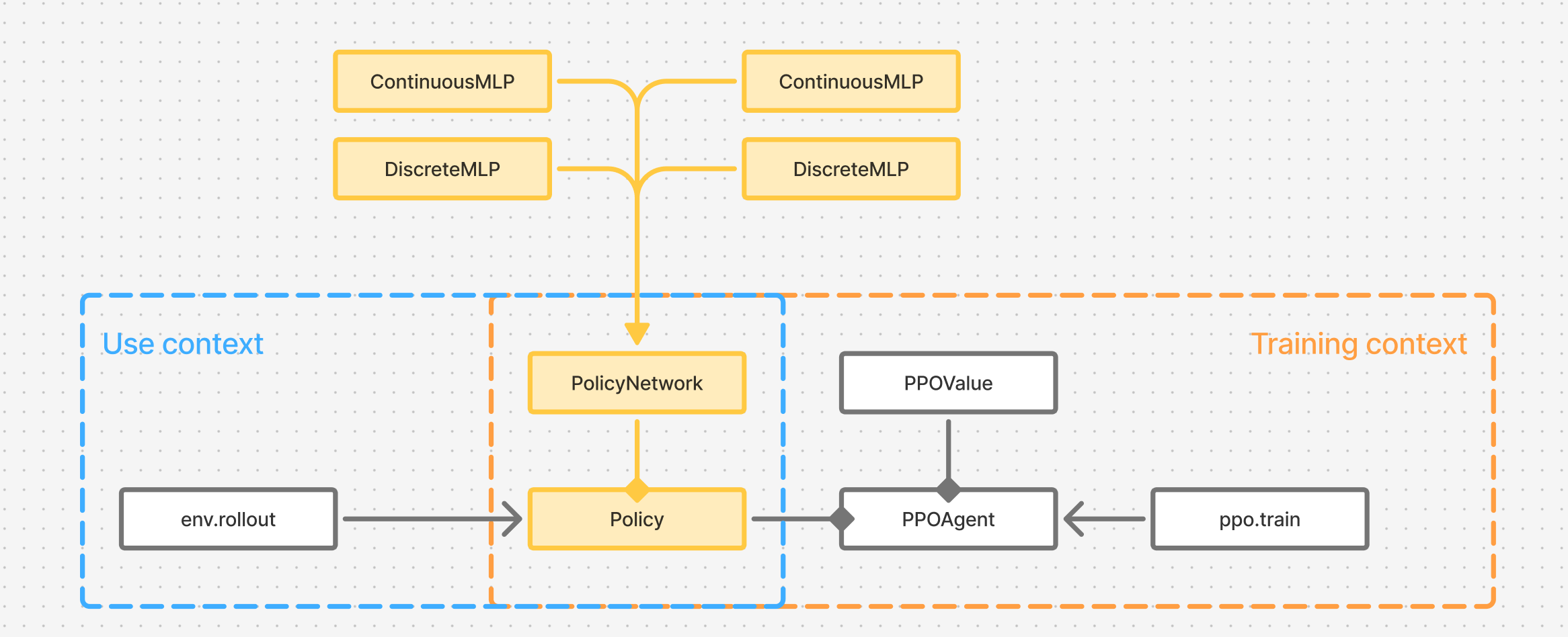
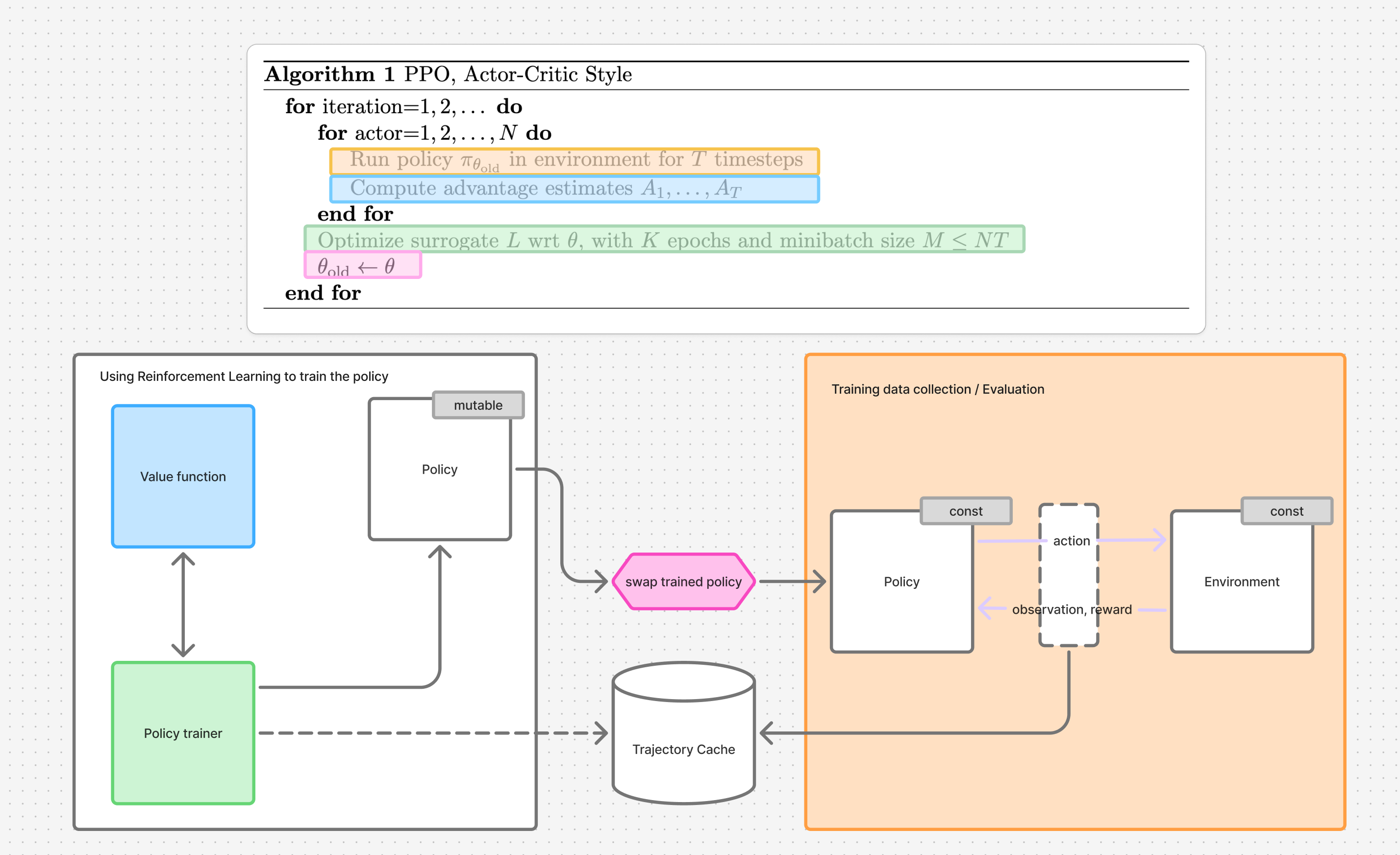
Figure 5. Relationship between the PPO training algorithm and the RL system design that uses PPO.
We can find it in section 5. In Figure 5 I colored the relevant components from Figure 4 to highlight the role they play in the algorithm
Step 2 Computing advantages
You will find references to those concepts showing up in Sections 2-5, with the definition of generalized advantage estimation presented in equation 11 and 12:

Notice the use of V(s_{t+1}) and V(s_{t}) - these are values obtained from the Value function, an auxiliary neural function that PPO algorithm introduces.
The code, implemented in pytorch, looks like this:
def compute_gae(
rewards: torch.Tensor,
values: torch.Tensor,
dones: torch.Tensor,
discount: float,
gae_lambda: float = 0.95,
) -> torch.Tensor:
"""Compute Generalized Advantage Estimation."""
advantages: list[torch.Tensor] = []
gae = torch.tensor(0.0)
for t in reversed(range(len(rewards))):
if t == len(rewards) - 1:
next_value = torch.tensor(
0.0
) # Bootstrap value (or get V(s_T) if not terminal)
else:
next_value = values[t + 1]
# Mask next_value if episode ended
next_value = next_value * (1 - dones[t])
# δ_t = r_t + γV(s_{t+1}) - V(s_t)
delta = rewards[t] + discount * next_value - values[t]
# A_t = δ_t + (γλ) δ_{t+1} + ... + (γλ)_{T-t+1}δ_{T-1}
gae = delta + discount * gae_lambda * (1 - dones[t]) * gae
advantages.insert(0, gae)
return torch.FloatTensor(advantages)
Step 3 Optimize surrogate L (loss)
Loss is defined in chapters 3 and 5
Clipped policy loss (chapter 3):
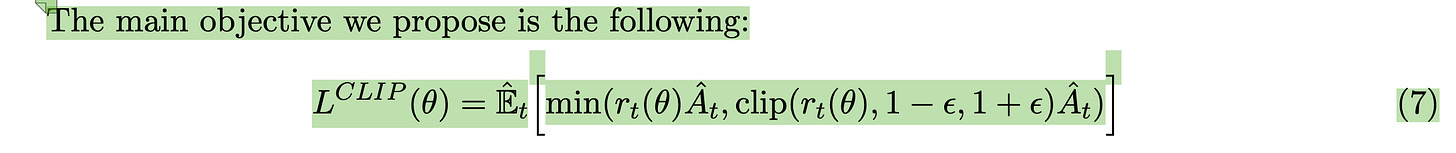
Full loss equation that combines the clipped policy loss with value function loss and entropy bonus (chapter 5):

PyTorch implementation of the loss looks like this:
class Trajectory(typing.NamedTuple):
states: torch.Tensor
actions: torch.Tensor
rewards: torch.Tensor
log_probs: torch.Tensor
dones: torch.Tensor
def ppo_loss(
agent: _PPOAgent, trajectory: Trajectory, discount: float, clip_eps: float
) -> torch.Tensor:
# LCLIP + L_VF + L_St(θ) = E_t[LCLIP_t(θ) − c_1 L_t^VF(θ) + c_2 S[πθ](st)]
log_probs, entropies = agent.policy.evaluate_actions(
trajectory.states, trajectory.actions
)
values = agent.value_fn(trajectory.states)
advantages = compute_gae(trajectory.rewards, values, trajectory.dones, discount)
returns = advantages + values
# Normalize advantages to stabilize training
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
assert log_probs.shape == (trajectory.states.shape[0],)
assert trajectory.log_probs.shape == (trajectory.states.shape[0],)
ratio = torch.exp(log_probs - trajectory.log_probs)
policy_loss = -torch.min(
ratio * advantages,
torch.clip(ratio, 1.0 - clip_eps, 1.0 + clip_eps) * advantages,
).mean()
value_loss = 0.5 * (returns - values).pow(2).mean()
c_2 = 0.01
entropy_loss = c_2 * entropies.mean()
loss = policy_loss + value_loss - entropy_loss
return loss
I am on purpose omitting the implementations of PPOPolicy and _PPOValue for the time being in order not to distract from the main objective of this section - the loss function.
Note that the loss function expects several values to be provided either as input or as the function of the policy, among them log probabilities and entropies.
Also notice that there are 2 sets of log probabilities - those calculated by the policy.evaluate_actions, and those provided as a part of the trajectory input.
Picking up on this implementation nuance requires jumping to the beginning of chapter 3 of the paper and looking at the definition of probability ratio that is used in clipped policy loss.
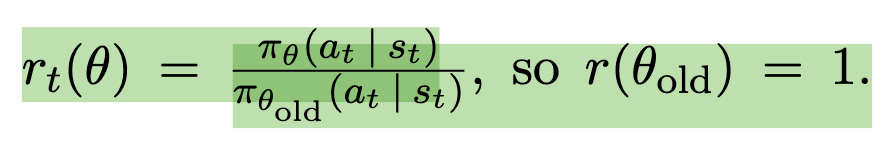
pi_{theta} and pi_{theta}_old refer to probabilities (but not the log probabilities), of actions generated by a new (in this context - trained) policy, and the old (in this context - the policy used to collect the trajectory).
An algorithmic trick that inolves taking a logarithm of this equation allows us to use log probabilities , which packages such as pytorch readily provide from their distribution implementations.
Step 4 Policy and Value function network architecture
This detail is described all the way in chapter 6

Step 5 Implementing the Policy function
At this point we can go ahead and implement the networks themselves.
To make the long story short - depending on the types of actions an environment works with - continuous or discrete - we need to interpret the logits returned by a model differently, and slightly change the architecture of the network
Policy base class
class PPOPolicy(nn.Module, abc.ABC):
def __init__(self, state_dim: int, action_dim: int) -> None:
super().__init__()
self.state_dim = state_dim
self.action_dim = action_dim
@abc.abstractmethod
def get_action(self, state: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
pass
@abc.abstractmethod
def evaluate_actions(
self, states: torch.Tensor, actions: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
pass
Implementation for the continuous action spaces trains the policy model to return parameters (1-st moments) of a gaussian distribution, and then samples those to return action values. An action is a vector of floating points - they may for example represent the speeds of motors rotating a robot’s arm:
class PPOPolicyContinuous(PPOPolicy):
def __init__(self, state_dim: int, action_dim: int) -> None:
super().__init__(state_dim, action_dim)
self.policy = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, 2 * action_dim),
)
def _get_action_distribution(self, state: torch.Tensor) -> dist.Distribution:
action_gaussian_params = self.policy(state)
means, log_stds = torch.chunk(action_gaussian_params, 2, dim=-1)
stds = torch.exp(log_stds.clamp(-20, 2))
return dist.Normal(loc=means, scale=stds)
def get_action(self, states: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"state should have shape (T, {self.state_dim}) != {states.shape}"
)
actions_dist = self._get_action_distribution(states)
action = actions_dist.sample()
# aggregate across the last dimension - we want the probability
# of the joint distribution of actions for a given timestep
log_prob = actions_dist.log_prob(action).sum(-1)
assert action.shape == (states.shape[0], self.action_dim)
assert log_prob.shape == (states.shape[0],)
return action, log_prob
def evaluate_actions(
self, states: torch.Tensor, actions: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"states should have shape (T, {self.state_dim}) != {states.shape}"
)
if len(actions.shape) != 2 or actions.shape[1] != self.action_dim:
raise ValueError(
f"actions should have shape (T, {self.action_dim}) != {actions.shape}"
)
actions_dist = self._get_action_distribution(states)
log_probs = actions_dist.log_prob(actions)
entropy = actions_dist.entropy()
# aggregate across the last dimension - we want the probability
# and the entropy of the joint distribution of actions for a given timestep
log_probs = log_probs.sum(-1)
entropy = entropy.sum(-1)
assert log_probs.shape == (states.shape[0],)
assert entropy.shape == (states.shape[0],)
return log_probs, entropy
Policy for discrete action spaces on the other hand assumes that the policy returns a single integer number that represents a discrete action to be taken by an environment. An example of such action is the index of an arrow key on a keyboard when we play one of atari games.
class PPOPolicyDiscrete(PPOPolicy):
def __init__(self, state_dim: int, action_dim: int) -> None:
super().__init__(state_dim, action_dim)
self.policy = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, action_dim),
)
def _get_action_distribution(self, state: torch.Tensor) -> dist.Distribution:
logits = self.policy(state)
logits = nn.functional.softplus(logits)
return dist.Categorical(logits)
def get_action(self, states: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"State should have shape (T, {self.state_dim}) != {states.shape}"
)
actions_dist = self._get_action_distribution(states)
action = actions_dist.sample()
log_prob = actions_dist.log_prob(action)
assert action.shape == (states.shape[0],)
assert log_prob.shape == (states.shape[0],)
return action, log_prob
def evaluate_actions(
self, states: torch.Tensor, actions: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"states should have shape (T, {self.state_dim}) != {states.shape}"
)
if len(actions.shape) != 1:
raise ValueError(f"actions should have shape (T,) != {actions.shape}")
actions_dist = self._get_action_distribution(states)
log_probs = actions_dist.log_prob(actions)
entropy = actions_dist.entropy()
assert log_probs.shape == (states.shape[0],)
assert entropy.shape == (states.shape[0],)
return log_probs, entropy
Step 6 Implementing the Value function
The value function uses the same network architecture, with the difference of returning a single floating point value - the value the function would assign to the state (observation) of an environment.
class _PPOValue(nn.Module):
def __init__(self, state_dim: int):
super().__init__()
self.value = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, 1),
)
def forward(self, states: torch.Tensor) -> torch.Tensor:
values = self.value(states)
return values.squeeze(
-1
) # squeeze returns a tensor that's shaped just like the rewards tensor
Complete code
Here’s the complete solution:
import abc
import logging
import typing
import gymnasium as gym
from gymnasium.wrappers import RecordVideo
import mlflow
import torch
import torch.distributions as dist
import torch.nn as nn
from tqdm import trange # type: ignore
def compute_gae(
rewards: torch.Tensor,
values: torch.Tensor,
dones: torch.Tensor,
discount: float,
gae_lambda: float = 0.95,
) -> torch.Tensor:
"""Compute Generalized Advantage Estimation."""
advantages: list[torch.Tensor] = []
gae = torch.tensor(0.0)
for t in reversed(range(len(rewards))):
if t == len(rewards) - 1:
next_value = torch.tensor(
0.0
) # Bootstrap value (or get V(s_T) if not terminal)
else:
next_value = values[t + 1]
# Mask next_value if episode ended
next_value = next_value * (1 - dones[t])
# δ_t = r_t + γV(s_{t+1}) - V(s_t)
delta = rewards[t] + discount * next_value - values[t]
# A_t = δ_t + (γλ) δ_{t+1} + ... + (γλ)_{T-t+1}δ_{T-1}
gae = delta + discount * gae_lambda * (1 - dones[t]) * gae
advantages.insert(0, gae)
return torch.FloatTensor(advantages)
class PPOPolicy(nn.Module, abc.ABC):
def __init__(self, state_dim: int, action_dim: int) -> None:
super().__init__()
self.state_dim = state_dim
self.action_dim = action_dim
@abc.abstractmethod
def get_action(self, state: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
pass
@abc.abstractmethod
def evaluate_actions(
self, states: torch.Tensor, actions: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
pass
class PPOPolicyContinuous(PPOPolicy):
def __init__(self, state_dim: int, action_dim: int) -> None:
super().__init__(state_dim, action_dim)
self.policy = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, 2 * action_dim),
)
def _get_action_distribution(self, state: torch.Tensor) -> dist.Distribution:
action_gaussian_params = self.policy(state)
means, log_stds = torch.chunk(action_gaussian_params, 2, dim=-1)
stds = torch.exp(log_stds.clamp(-20, 2))
return dist.Normal(loc=means, scale=stds)
def get_action(self, states: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"state should have shape (T, {self.state_dim}) != {states.shape}"
)
actions_dist = self._get_action_distribution(states)
action = actions_dist.sample()
# aggregate across the last dimension - we want the probability
# of the joint distribution of actions for a given timestep
log_prob = actions_dist.log_prob(action).sum(-1)
assert action.shape == (states.shape[0], self.action_dim)
assert log_prob.shape == (states.shape[0],)
return action, log_prob
def evaluate_actions(
self, states: torch.Tensor, actions: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"states should have shape (T, {self.state_dim}) != {states.shape}"
)
if len(actions.shape) != 2 or actions.shape[1] != self.action_dim:
raise ValueError(
f"actions should have shape (T, {self.action_dim}) != {actions.shape}"
)
actions_dist = self._get_action_distribution(states)
log_probs = actions_dist.log_prob(actions)
entropy = actions_dist.entropy()
# aggregate across the last dimension - we want the probability
# and the entropy of the joint distribution of actions for a given timestep
log_probs = log_probs.sum(-1)
entropy = entropy.sum(-1)
assert log_probs.shape == (states.shape[0],)
assert entropy.shape == (states.shape[0],)
return log_probs, entropy
class PPOPolicyDiscrete(PPOPolicy):
def __init__(self, state_dim: int, action_dim: int) -> None:
super().__init__(state_dim, action_dim)
self.policy = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, action_dim),
)
def _get_action_distribution(self, state: torch.Tensor) -> dist.Distribution:
logits = self.policy(state)
logits = nn.functional.softplus(logits)
return dist.Categorical(logits)
def get_action(self, states: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"State should have shape (T, {self.state_dim}) != {states.shape}"
)
actions_dist = self._get_action_distribution(states)
action = actions_dist.sample()
log_prob = actions_dist.log_prob(action)
assert action.shape == (states.shape[0],)
assert log_prob.shape == (states.shape[0],)
return action, log_prob
def evaluate_actions(
self, states: torch.Tensor, actions: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
if len(states.shape) != 2 or states.shape[1] != self.state_dim:
raise ValueError(
f"states should have shape (T, {self.state_dim}) != {states.shape}"
)
if len(actions.shape) != 1:
raise ValueError(f"actions should have shape (T,) != {actions.shape}")
actions_dist = self._get_action_distribution(states)
log_probs = actions_dist.log_prob(actions)
entropy = actions_dist.entropy()
assert log_probs.shape == (states.shape[0],)
assert entropy.shape == (states.shape[0],)
return log_probs, entropy
class _PPOValue(nn.Module):
def __init__(self, state_dim: int):
super().__init__()
self.value = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, 1),
)
def forward(self, states: torch.Tensor) -> torch.Tensor:
values = self.value(states)
return values.squeeze(
-1
) # squeeze returns a tensor that's shaped just like the rewards tensor
class Trajectory(typing.NamedTuple):
states: torch.Tensor
actions: torch.Tensor
rewards: torch.Tensor
log_probs: torch.Tensor
dones: torch.Tensor
def enable_grad(self) -> None:
self.states.requires_grad = self.states.dtype.is_floating_point
self.actions.requires_grad = self.actions.dtype.is_floating_point
self.log_probs.requires_grad = self.log_probs.dtype.is_floating_point
self.rewards.requires_grad = self.rewards.dtype.is_floating_point
self.dones.requires_grad = self.dones.dtype.is_floating_point
def __len__(self) -> int:
if self.states is not None and len(self.states.shape) >= 1:
return self.states.shape[0]
else:
return 0
@staticmethod
def concat(lhs: typing.Optional["Trajectory"], rhs: "Trajectory") -> "Trajectory":
if lhs is None:
return rhs
return Trajectory(
torch.concat([lhs.states, rhs.states]),
torch.concat([lhs.actions, rhs.actions]),
torch.concat([lhs.rewards, rhs.rewards]),
torch.concat([lhs.log_probs, rhs.log_probs]),
torch.concat([lhs.dones, rhs.dones]),
)
class _PPOAgent(nn.Module):
def __init__(self, policy: PPOPolicy, value_fn: _PPOValue) -> None:
super().__init__()
self.policy = policy
self.value_fn = value_fn
def ppo_loss(
agent: _PPOAgent, trajectory: Trajectory, discount: float, clip_eps: float
) -> torch.Tensor:
# LCLIP + L_VF + L_St(θ) = E_t[LCLIP_t(θ) − c_1 L_t^VF(θ) + c_2 S[πθ](st)]
log_probs, entropies = agent.policy.evaluate_actions(
trajectory.states, trajectory.actions
)
values = agent.value_fn(trajectory.states)
advantages = compute_gae(trajectory.rewards, values, trajectory.dones, discount)
returns = advantages + values
# Normalize advantages to stabilize training
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
assert log_probs.shape == (trajectory.states.shape[0],)
assert trajectory.log_probs.shape == (trajectory.states.shape[0],)
ratio = torch.exp(log_probs - trajectory.log_probs)
policy_loss = -torch.min(
ratio * advantages,
torch.clip(ratio, 1.0 - clip_eps, 1.0 + clip_eps) * advantages,
).mean()
value_loss = 0.5 * (returns - values).pow(2).mean()
c_2 = 0.01
entropy_loss = c_2 * entropies.mean()
loss = policy_loss + value_loss - entropy_loss
return loss
def train_one_trajectory(
agent: _PPOAgent,
optimizer: torch.optim.Optimizer,
trajectory: Trajectory,
num_updates: int,
discount: float = 0.95,
clip_eps: float = 0.2,
) -> list[torch.Tensor]:
"""Trains the PPO policy and value networks on a single trajectory.
Multiple steps of training are preformed, the number defined by `num_updates` parameter.
After calling this function, `trajectory` should be discarded and a new trajectory should be
sampled.
"""
trajectory.enable_grad()
losses: list[torch.Tensor] = []
for _ in trange(num_updates, desc="PPO update step", leave=False):
optimizer.zero_grad()
loss = ppo_loss(agent, trajectory, discount, clip_eps)
losses.append(loss)
loss.backward()
# TODO: does gradient clipping fix training?
# nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
optimizer.step()
return losses
def rollout_episode(env, policy: PPOPolicy, max_trajectory_len: int) -> Trajectory:
states, rewards, actions, log_probs = [], [], [], []
dones: list[int] = []
state = env.reset()[0]
done = False
num_steps = 0
with torch.no_grad():
while not done and num_steps < max_trajectory_len:
state_t = torch.tensor(state)
one_state_in_batch_t = state_t.unsqueeze(0)
action_t, log_prob_t = policy.get_action(one_state_in_batch_t)
# Extract the only action and log probability from the batch tensor
log_prob_f = log_prob_t.detach()[0]
action_f = action_t.detach()[0]
next_state, reward, done, _, _ = env.step(action_f.numpy())
states.append(state_t)
actions.append(action_f)
rewards.append(reward)
log_probs.append(log_prob_f)
dones.append(1 if done else 0)
state = next_state
num_steps += 1
if not states:
raise RuntimeError("No trajectory rolled out")
states_t = torch.stack(states)
actions_t = torch.stack(actions)
rewards_t = torch.tensor(rewards)
log_probs_t = torch.stack(log_probs)
dones_t = torch.tensor(dones)
assert states_t.shape == (num_steps, policy.state_dim)
assert rewards_t.shape == (num_steps,)
assert log_probs_t.shape == (num_steps,)
assert dones_t.shape == (num_steps,)
if isinstance(policy, PPOPolicyContinuous):
assert actions_t.shape == (num_steps, policy.action_dim)
elif isinstance(policy, PPOPolicyDiscrete):
assert actions_t.shape == (num_steps,)
else:
raise TypeError(f"Unsupported policy type {type(policy)}")
return Trajectory(states_t, actions_t, rewards_t, log_probs_t, dones_t)
def train(
env,
policy: PPOPolicy,
num_updates_per_epoch: int,
num_episodes_per_epoch: int,
num_epochs: int,
max_trajectory_len: int,
discount: float = 0.95,
clip_eps: float = 0.2,
) -> None:
# TODO: how to implement learning rate decay?
value_fn = _PPOValue(policy.state_dim)
agent = _PPOAgent(policy, value_fn)
optimizer = torch.optim.Adam(agent.parameters(), lr=3e-4)
experiment = mlflow.set_experiment("PPO training")
with mlflow.start_run(experiment_id=experiment.experiment_id):
mlflow.log_param("torch_version", torch.__version__)
mlflow.log_param("cuda_available", torch.cuda.is_available())
mlflow.log_param("num_updates_per_epoch", num_updates_per_epoch)
mlflow.log_param("num_episodes_per_epoch", num_episodes_per_epoch)
mlflow.log_param("num_epochs", num_epochs)
mlflow.log_param("max_trajectory_len", max_trajectory_len)
mlflow.log_param("discount", discount)
mlflow.log_param("clip_eps", clip_eps)
if torch.cuda.is_available():
mlflow.log_param("cuda_device_count", torch.cuda.device_count())
try:
mlflow.log_param("cuda_device_name", torch.cuda.get_device_name(0))
except Exception:
pass
total_params = sum(p.numel() for p in agent.parameters())
trainable_params = sum(p.numel() for p in agent.parameters() if p.requires_grad)
mlflow.log_param("total_parameters", total_params)
mlflow.log_param("trainable_parameters", trainable_params)
mlflow.log_param(
"trainable_percentage", 100.0 * trainable_params / total_params
)
for epoch in trange(num_epochs, desc="train", leave=False):
trajectory = None
for _ in trange(
num_episodes_per_epoch, desc="Collecting trajectory", leave=False
):
traj_step = rollout_episode(env, policy, max_trajectory_len)
trajectory = Trajectory.concat(trajectory, traj_step)
if len(trajectory) > max_trajectory_len:
break
if trajectory is None:
logging.warning("Trajectory not collected")
return
mlflow.log_metric("traj_len", trajectory.states.shape[0], step=epoch)
losses = train_one_trajectory(
agent, optimizer, trajectory, num_updates_per_epoch, discount, clip_eps
)
losses_t = torch.stack(losses)
mlflow.log_metric("loss", float(losses_t.mean()), step=epoch)
# evaluation
# TODO: extract to a separate function - but it will require extracting mlflow initialization
# to log artifacts to the same run
env_eval: RecordVideo = RecordVideo(
env,
video_folder="./videos/",
episode_trigger=lambda x: (x % 10 == 0), # record every 10th episode
name_prefix="ppo-lunarlander",
)
with torch.no_grad():
for eval_epoch in trange(num_epochs, desc="eval", leave=False):
trajectory = rollout_episode(env_eval, policy, max_trajectory_len)
loss = ppo_loss(agent, trajectory, discount, clip_eps)
mlflow.log_metric("eval loss", float(loss), step=eval_epoch)
def main():
env = gym.make("LunarLander-v3", render_mode="rgb_array")
action_dim = int(env.action_space.n)
state_dim = env.reset()[0].shape[0]
policy = PPOPolicyDiscrete(state_dim=state_dim, action_dim=action_dim)
train(
env,
policy,
num_updates_per_epoch=20,
num_episodes_per_epoch=10,
num_epochs=100,
max_trajectory_len=1000,
)
if __name__ == "__main__":
main()
It was written and tested with Python 3.14 and uses the following dependencies:
gymnasium[box2d,other]>=1.2.3
mlflow>=3.3.1
pydantic>=2.11.7
swig>=4.4.1
torch>=2.9.0
tqdm>=4.67.1
Conclusion
I’d love to hear you comments and thoughts on the topic.
The point here was to show that implementing a Deep Learning algorithm from a whitepaper is not a straightforward challenge and to encourage you to do it.
]]>





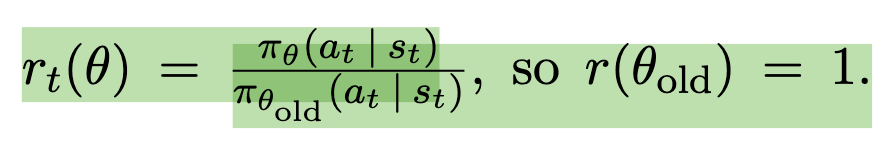


{kind=link}